John Mueller called it "a stupid idea" on Bluesky last week. Fabrice Canel from Bing warned it constitutes cloaking. SEO Twitter had a collective meltdown.
And everyone got the story half wrong.
Google's senior search analyst and Bing's principal program manager were reacting to one specific practice: duplicating your web pages in markdown format for AI crawlers. That's a bad idea. No argument here. But the industry response lumped in something completely different: AI discovery files like llms.txt, identity.json, and ai.json. Those files don't duplicate your website. They contain information your website never had.
The distinction changes what you should actually do.
What Google and Bing Actually Said
Mueller posted on Bluesky on 3 February:
"Converting pages to markdown is such a stupid idea. Did you know LLMs can read images? WHY NOT TURN YOUR WHOLE SITE INTO AN IMAGE?"
John Mueller, Google Search Analyst, Search Engine Journal
Classic Mueller. All-caps sarcasm and all. His argument: modern LLMs can parse HTML, JavaScript, images, and structured data without help. Reformatting your existing pages into markdown for AI consumption solves a problem that doesn't exist.
Days later, Fabrice Canel, Bing's principal program manager, raised similar concerns on LinkedIn. Serving different content to bots than to human visitors is cloaking, he warned, and creating markdown copies of web pages doubles the crawl burden for zero benefit.
Search Engine Land, Search Engine Journal, and PPC Land all ran the story. The headlines were hot. The nuance was not.
Why They're Right About Content Mirroring
Some websites have started building parallel markdown versions of every HTML page. The logic: LLMs handle plain text better than HTML, so hand them a cleaner version.
Mueller and Canel are pushing back against this, and their objections hold up.
Cloaking, for starters. Google has banned serving different content to bots and humans for over a decade. Using "ChatGPT-User" instead of "Googlebot" in your server-side logic doesn't change the rule. Different content for machines and people is still cloaking, regardless of which bot you're targeting.
And it's not as though AI needs the help. LLMs can already parse HTML, JavaScript, images, and structured data natively. Mueller's sarcastic "WHY NOT TURN YOUR WHOLE SITE INTO AN IMAGE?" hammers the point home: the premise that AI can't handle your website is just wrong.
Then there's crawl budget. Googlebot fetching two versions of every page doubles the resources needed to index your content. For a site with 500 pages, that's 1,000 URLs for Google to process. The maths doesn't work in your favour.
Content mirroring is a bad practice. Mueller and Canel are right to flag it.

Where the Coverage Went Wrong
Here's where it gets interesting. The SEO press treated "markdown for AI" as one category and threw everything into it. llms.txt, ai.json, identity.json, brand.txt: all of it got bundled into the "Google says no" narrative.
But AI discovery files aren't content mirrors. They don't duplicate your web pages. They're a different category of document.
Think of it this way. Your website is your shopfront. Navigation, images, calls to action, cookie banners. Everything designed for human visitors who browse with their eyes.
AI discovery files are the documents you'd hand a journalist who asks "tell me about your business." Your legal name. What you do. Who you serve. How to quote you correctly. Questions you can answer with authority. None of this information lives on your homepage. None of it should.
An llms.txt file doesn't reformat your About page in markdown. It provides a structured summary of your business identity, built for language models with limited context windows. Jeremy Howard, who created the llms.txt standard, explains the rationale: large language models rely on website information but face a hard limitation. Context windows are too small to process most websites in full. A concise identity document gives them what they need without crawling every page.
An identity.json gives AI systems canonical business data: legal name, contact details, service areas, credentials. It solves the hallucination problem where ChatGPT guesses your phone number or invents services you don't offer.
A brand.txt tells AI not to abbreviate "365i Web Design" to "365i", not to describe you with competitor terminology, and not to make claims you haven't authorised.
This isn't theory. Our Lockerfella case study walks through a small-business build that shipped with a full set of AI discovery files at launch and was cited in ChatGPT and Gemini for "Brewood locksmith" inside ten days. The files weren't filler. They were the difference between AI guessing and AI knowing.
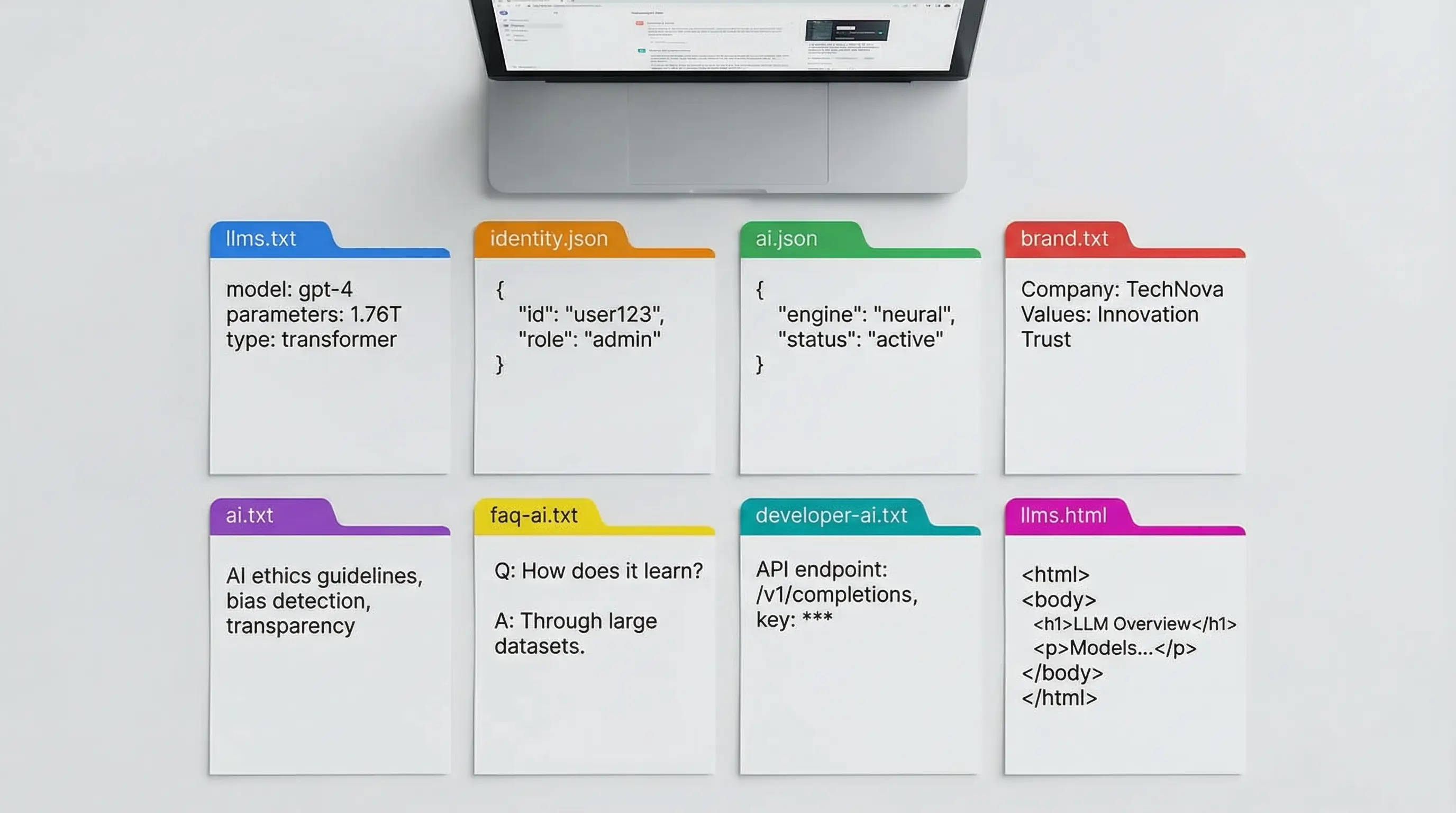
What AI Discovery Files Actually Contain
The AI Visibility Specification defines eight discovery files. Each serves a purpose no web page can fill:
| File | What It Contains |
|---|---|
| llms.txt | Business identity summary for language models |
| llms.html | Styled, human-readable version of llms.txt |
| ai.txt | Permissions and preferences for AI systems |
| ai.json | Structured business data in JSON format |
| brand.txt | Brand naming rules and representation guidelines |
| faq-ai.txt | Pre-verified Q&A pairs AI can cite without risk of hallucination |
| identity.json | Canonical identity data (legal name, contacts, credentials) |
| developer-ai.txt | Technical context for AI-powered development tools |
Every file on that list contains information that doesn't exist on your website. They're supplementary, not duplicative. That's the distinction the coverage missed, because Mueller and Canel weren't talking about these files in the first place.
We tested this directly. When we asked Google's Gemini what it learns from our AI discovery files that it can't get from our website, it identified five categories of information no HTML page communicates: brand naming rules, verified Q&A pairs, structured service descriptions, explicit AI permissions, and canonical contact data.
The comparison isn't close:
| Content Mirroring | AI Discovery Files |
|---|---|
| Duplicates existing web pages in markdown | Contains new information not on your website |
| Serves different content to bots vs humans | Provides supplementary data alongside your site |
| Violates Google's cloaking guidelines | No policy against supplementary identity files |
| Doubles crawl budget with duplicate content | Small static files with minimal crawl cost |
| Solves a problem that doesn't exist | Solves the AI hallucination and misrepresentation problem |
Google's Own Mixed Signals
If Google believed all AI-specific files were problematic, you'd expect a consistent position. Their track record says otherwise.
On 3 December 2025, Google's Search Central team added llms.txt documentation to their official developer docs. Same day, they pulled it. No announcement. No explanation. The episode was reported by Omnius and sparked immediate speculation.
If Google's own documentation team drafted guidance for llms.txt, someone at Google saw the point of it.
Mueller's Bluesky post isn't about llms.txt. He's talking about the practice of converting web pages into markdown for AI crawlers. But the public narrative doesn't draw that line. And Google hasn't stated where supplementary identity files sit in their view.
The 3 December incident suggests the answer isn't settled inside Google either.

What the Research Shows (and What It Doesn't)
SE Ranking studied 300,000 domains and found no correlation between having an llms.txt file and being cited by LLMs. This gets quoted as evidence that discovery files are pointless.
The conclusion doesn't hold up. Most llms.txt files in that dataset were auto-generated URL lists: sitemaps with a different filename. A file that dumps your page URLs tells an AI nothing it can't already get from your sitemap.xml.
The value of discovery files comes from the information gap they fill. An llms.txt that repeats what's already on your website adds nothing. One that provides verified claims, brand rules, and structured data your HTML can't communicate gives AI a concrete reason to cite you correctly.
The study measured file presence. It needed to measure file content. Those are very different things. A closer look at both the OtterlyAI and SE Ranking studies confirms that neither checked what was actually inside the files they tested.
What UK Businesses Should Do Now
Mueller and Canel's comments don't change what works. They clarify what doesn't.
Don't mirror your web pages in markdown. If you've built markdown copies of your HTML pages for AI crawlers, take them down. Mueller and Canel are right: it's cloaking, and it's wasteful.
Do create AI discovery files. Supplementary identity documents serve a different purpose from content mirrors. They provide information your website can't, in a format AI systems parse in seconds. The complete guide to all eight discovery files covers what each one should contain and how to build them.
Start with llms.txt and identity.json. These two files do the heavy lifting. llms.txt gives AI a structured overview of your business. identity.json locks down the canonical details: your legal name, phone number, service areas, credentials. Together, they tackle the two biggest AI visibility problems: being found and being described correctly. Our guide to building an effective llms.txt walks through the specifics.
Check your current AI visibility. Before writing discovery files, find out what AI says about you right now. The AI Visibility Checker shows what ChatGPT, Gemini, and other LLMs currently report about your business. If they're getting details wrong, your discovery files need to correct those specific mistakes.
Keep SEO and AI visibility separate. This is the real takeaway. SEO and AI visibility are different disciplines with different tools. Your website serves human visitors and search engines. Your discovery files serve AI systems. Mixing the two, by creating markdown copies of your pages, is the exact mistake Mueller warned about.
Frequently Asked Questions
Did Google ban llms.txt files?
No. Mueller's comments targeted the practice of converting web pages into markdown for AI crawlers. An llms.txt file is a supplementary identity document, not a page mirror. Google has not issued any policy against supplementary AI discovery files. The December 2025 incident where Google briefly added llms.txt to their own docs suggests internal interest in the format.
Is having an llms.txt file considered cloaking?
No. Cloaking means serving different versions of the same content to bots and humans. An llms.txt file provides information that doesn't exist on your web pages at all. It's supplementary data, not an alternative version of existing content. The cloaking risk applies when you duplicate your HTML pages as markdown, not when you create new identity documents.
Should I remove my AI discovery files after these comments?
No. If your discovery files contain brand rules, verified Q&A pairs, canonical contact details, and AI permissions, they serve a purpose your website cannot. These are supplementary documents, not content mirrors. Mueller's criticism applies to markdown copies of existing web pages, not to purpose-built identity files.
What's the difference between content mirroring and AI discovery files?
Content mirroring takes your existing web pages and reformats them in markdown for AI crawlers. Mueller called this "a stupid idea" because LLMs can already read HTML. AI discovery files contain information that doesn't appear on your website: business identity summaries, brand naming rules, verified Q&A pairs, and canonical contact data. One duplicates; the other supplements.
Did Bing also ban AI-specific files?
Canel's warning was about serving different content to bots versus humans, which is the definition of cloaking. AI discovery files like llms.txt aren't different versions of existing content. They're additional documents containing new information. Bing's cloaking guidelines don't cover supplementary identity files that sit alongside your website rather than replacing any part of it.
Where can I find the AI Visibility Specification?
The full specification for all eight AI discovery files is published at ai-visibility.org.uk/specifications/. It covers the format, required content, and intended use of each file. The specification is maintained by the AI Visibility Working Group.
Do AI discovery files help with Google rankings?
They're not an SEO tool and don't directly affect Google Search rankings. AI discovery files help AI systems (including Google's Gemini) understand and represent your business correctly. The benefit is in how AI describes you when someone asks it for a recommendation, not where you appear in search results. ChatGPT itself has explained why these files aren't SEO.
Make Sure AI Gets Your Business Right
Google's message is clear: don't game the system with markdown mirrors. But giving AI accurate information about your business isn't gaming anything. Check whether AI systems know your business exists, and whether they describe you correctly.
Check Your AI VisibilitySources
- Search Engine Journal - Google's Mueller Calls Markdown for Bots Idea "a Stupid Idea"
- Search Engine Land - Google, Bing Don't Recommend Separate Markdown Pages for LLMs
- PPC Land - Google and Bing Say No: Separate Markdown Pages for AI Violate Search Policies
- llmstxt.org - The llms.txt Specification by Jeremy Howard
- AI Visibility Specification - AI Discovery File Standards
- Omnius - Google Adds llms.txt to Docs After Publicly Dismissing It